XR Medium
Governance By Architecture, Not Discipline
GenAI-Logic Governance architecture
Business logic governance has always been a structural problem. Procedural code — human-written or AI-generated — must explicitly handle every change path. Every team misses some. The bugs are silent, the costs are real, and they accumulate quietly across the codebase.
Every generation has tried to solve this with a new path. Fat clients put logic in the UI — bypassed by every other channel. Fat APIs moved it to the service layer — bypassed by direct database access or the next service. Each architecture became the next one's escape route. The problem was never which path held the logic. It was that logic on any path can be bypassed by another path.
Agentic AI is the newest instance. New agents touch production data, multiply the paths, and turn a chronic problem into a recognized one — AI Governance ranks #1 among CIO priorities in 2026, overtaking cybersecurity for the first time (to see the report, click here ).
But the architecture required to govern AI agents is the same architecture that governs traditional logic. As paths multiply — and as the org scales from one project to hundreds — discipline is not enough. An architecture is required.
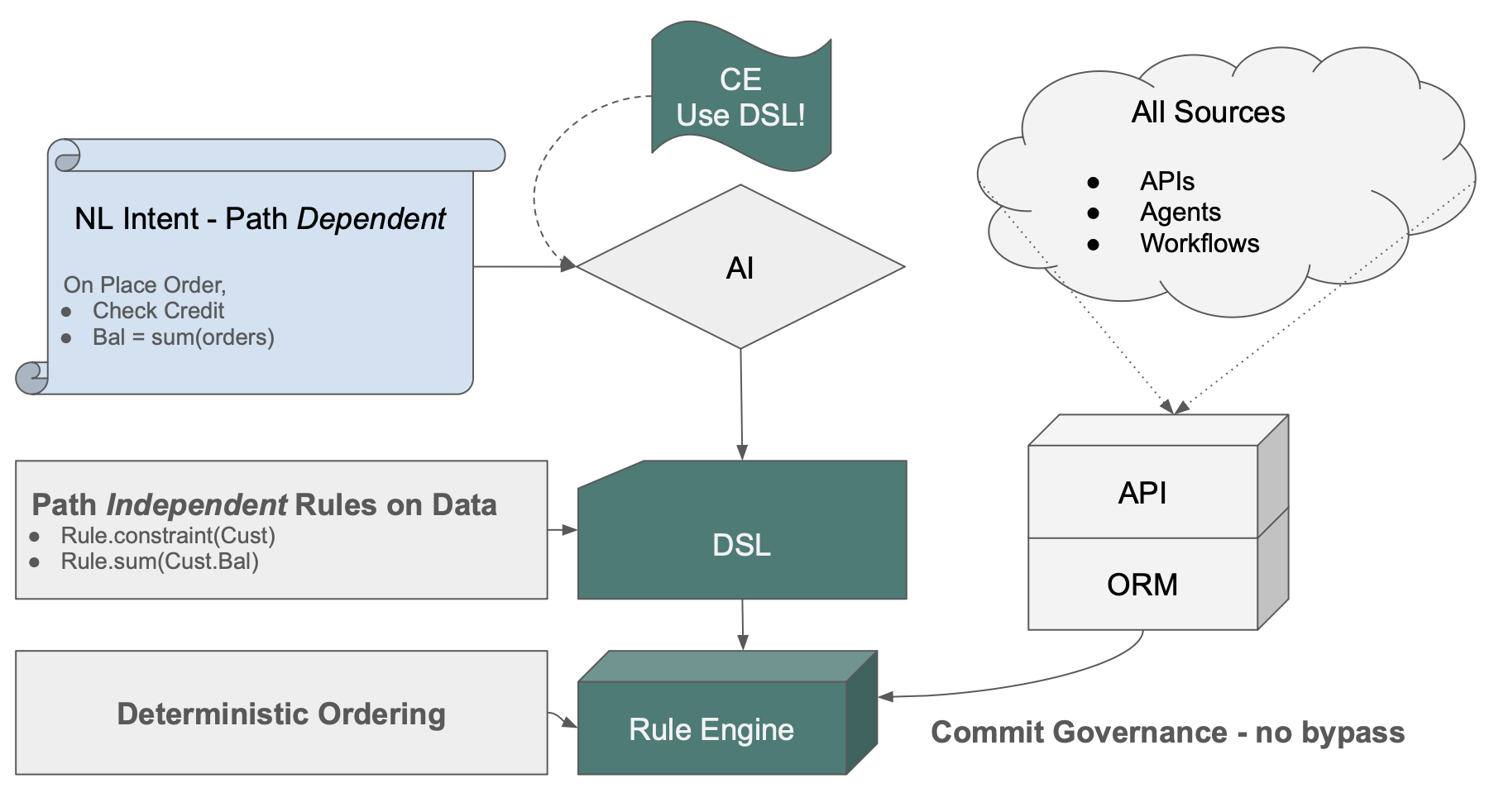
We've created such a governance architecture:
- Context Engineering directs AI to generate Data Rules — not procedural code. Intent becomes declarations.
- Data Rules distill path-dependent logic into path-independent rules on data. See them below —
Rule.constraint, Rule.sum. No missed paths. Every path inherits them automatically. - The Commit Listener hooks into the ORM commit. Every transaction — API, agent, workflow — passes through one control point. Nothing bypasses it.
- The Rule Engine computes dependency order from the Data Rules at startup — deterministically. No pattern-matching, no subtle ordering bugs.
The AI Agent Problem
Every enterprise deploying AI agents faces the same question: what happens when the agent touches production data? Prompts can be crafted carefully. Models can be fine-tuned. But none of that governs what actually persists to the database.
The Commit Listener answers this architecturally. Every transaction — whether from a human API call, a workflow, or an AI agent — passes through one control point. The agent cannot bypass it. Neither can a new developer, a new endpoint, or a carefully crafted prompt.
This governs every transaction through the ORM — the path all well-behaved application code takes. Direct database connections bypass this layer, as they would any application server; those require standard database-level controls.
But a commit listener is only as trustworthy as the logic it enforces. That’s where most governance approaches fail — procedural code has bugs, and a governance layer built on buggy logic is just a faster path to wrong answers.
The Correctness Problem
Ask AI to implement those same five business rules as procedural code — it generates 220 lines. 44X. That alone should give pause. But the deeper problem is correctness.
When we ran this experiment, Copilot's procedural code had critical bugs — discovered only after prompting. We asked: "What if the order's customer changes?" — it found a bug. "What if the item's product changes?" — another bug. Both the same failure: a foreign key change that updated the new parent's balance but left the old parent's balance uncorrected. Silent. No exception. Wrong data persisting to the database.
5 rules. 0 bugs. 220 lines. 2 bugs — found only when asked. That gap is not a productivity argument. It's a correctness argument.
This is not a criticism of AI capability. It's structural — the same problem that has plagued procedural business logic for decades. Procedural code must explicitly handle every change path — quantity changes, product changes, customer reassignment, order deletion, shipment. The dependency graph has exponential combinations. No developer enumerates them all. No AI can either. The bugs are silent, and they ship. See the study.
The Governance Architecture addresses this by delegating dependency management to the rules engine. Dependencies are computed at startup, deterministically — automatic invocation, automatic ordering, every path covered. Not because a developer remembered to handle it. Because the architecture cannot miss it.
Consequence: Executable Requirements
This is what the architecture produces: requirements that are executable. The same Gherkin a business analyst writes becomes what the rule engine enforces — at commit time, on every path, with no bypass.
Some setup, then a single prompt creates a running system — logic, custom APIs, messaging, and security. This is the entire system, not a prototype.
Initial Creation
The setup below creates a project from an existing database — standard Python, open in your IDE, ready to run:
-
JSON:API: an endpoint for each table, with pagination, optimistic locking, filtering, sorting, etc. With Swagger.
- In minutes, you have an MCP-discoverable API. Vibe custom UIs.
-
Admin App: a multi-table admin app, providing master detail, lookups, etc.
# A - Create project from existing database
genai-logic create --project_name=demo_eai --db_url=sqlite:///samples/dbs/basic_demo.sqlite
# B - In created project, get these requirements
$ cp -r ../samples/requirements/demo_eai/ .
# C - Optionally, configure security
$ (cd devops/keycloak; docker compose up -d)
$ genai-logic add-auth --provider-type=keycloak --db-url=localhost
# D - Create system from requirements
implement requirements docs/requirements/demo_eai
The following is the exact prompt (steps 1-6) you can then submit to create logic, custom APIs, Messaging, and Security. AI uses the Context Engineering to create executable software from the actual requirements below (step D).
1. Business Logic — Check Credit
Feature: Check Credit
Scenario: Place an order
Given a customer with a credit limit
When an order is placed
Then copy the price from the product
And multiply by quantity to get the item amount
And sum item amounts to get the order total
And sum unpaid order totals to get the customer balance
And reject if balance exceeds the credit limit
2. B2B API — Accept orders from external partners
Feature: B2B Order Integration
Scenario: Accept order from external partner
Given an inbound B2B order in partner format (message_formats/order_b2b.json)
When the order is received via a Custom API endpoint named OrderB2B
Then map Account to Customer by name
And map Items.Name to Product by name
And map Items.QuantityOrdered to Item.quantity
And create the order with all Check Credit rules enforced
3. Kafka Subscribe — Inbound orders from sales channel
Feature: Kafka Subscribe Order Integration
Scenario: Accept inbound orders from sales channel
Given an inbound order message in JSON format (message_formats/order_b2b.json)
When the message is received from Kafka topic order_b2b
Then use the 2-message pattern
And save the raw payload as a blob in the first transaction
And parse and persist the order in the second transaction
And map Account to Customer by name
And map Items.Name to Product by name
And map Items.QuantityOrdered to Item.quantity
And create the order with all Check Credit rules enforced
4. Kafka Publish — Notify shipping on dispatch
Feature: Kafka Publish Shipping Notification
Scenario: Notify shipping when an order is dispatched
Given an Order exists
When date_shipped is set
Then publish to Kafka topic order_shipping
And use message_formats/order_shipping.json as the message shape
And use by-example publish rather than key-only publish
5. Security
Feature: Row-Level Security
Scenario: Sales role sees limited customers
Given a user with the sales role
When querying the Customer list
Then only return customers where credit_limit >= 3000 or balance > 0
Any Source, Any Path
Directed by Context Engineering, AI generates Data Rules in Python — from Gherkin (Step 1,above) or plain text (below).
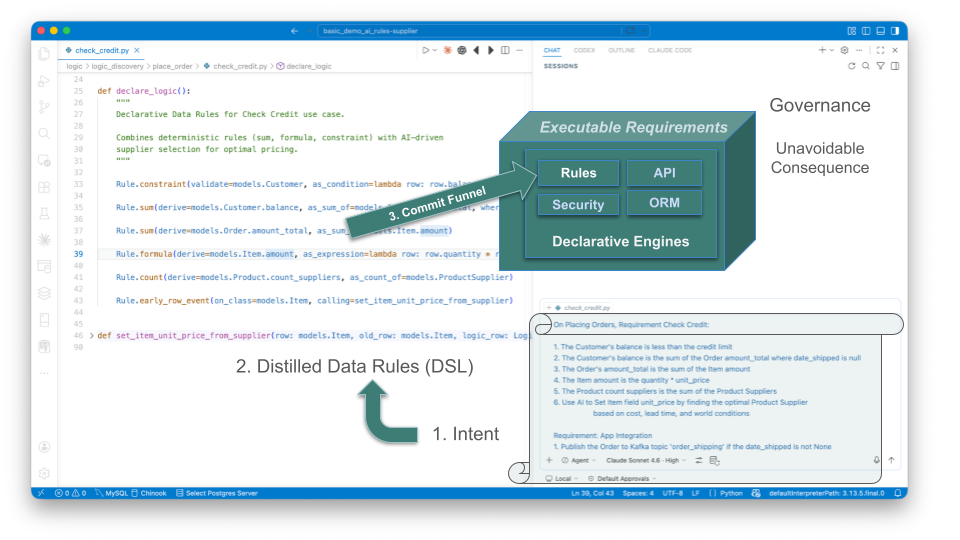
The rules execute on commit — any commit.
- Any source - APIs and messages are all funneled into the commit gate, automatically. No bypass.
- Any path - The resultant logic governs eight scenarios... the Gherkin specified one. Delete an order — nobody mentioned that. Ship an order — nobody mentioned that. An agent updates a quantity — not in the spec. Yet, all enforce the rules, because the rules are on the data, not the path. They don't know or care which scenario triggered the transaction. A new developer adds an endpoint next month. A new agent connects next year. Both inherit the same rules — automatically, with no additional work.
You designed one scenario. The architecture governed all of them.
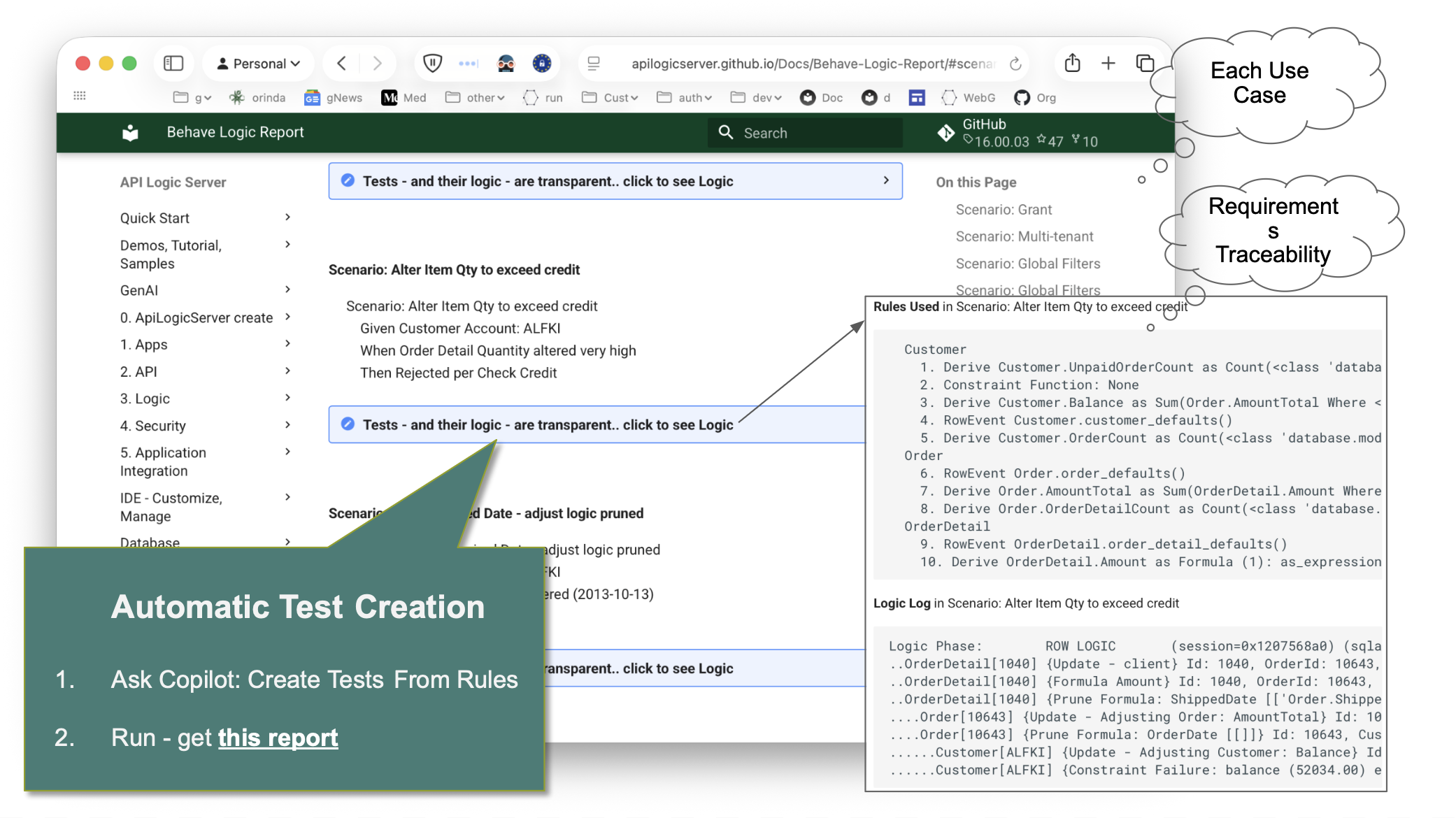
The formalized rules also enable the system to create and run tests directly from rules. These don't just demonstrate requirements are fulfilled — they make the requirement → rules → execution log visible to the entire organization: developers, business users, auditors.
Making AI Wise
The Rules Engine is fundamental to Governance. It is what executes the distilled rules above.
Purpose-built for transaction processing (non-RETE), it is a sophisticated piece of software, similar in complexity to a relational query engine.
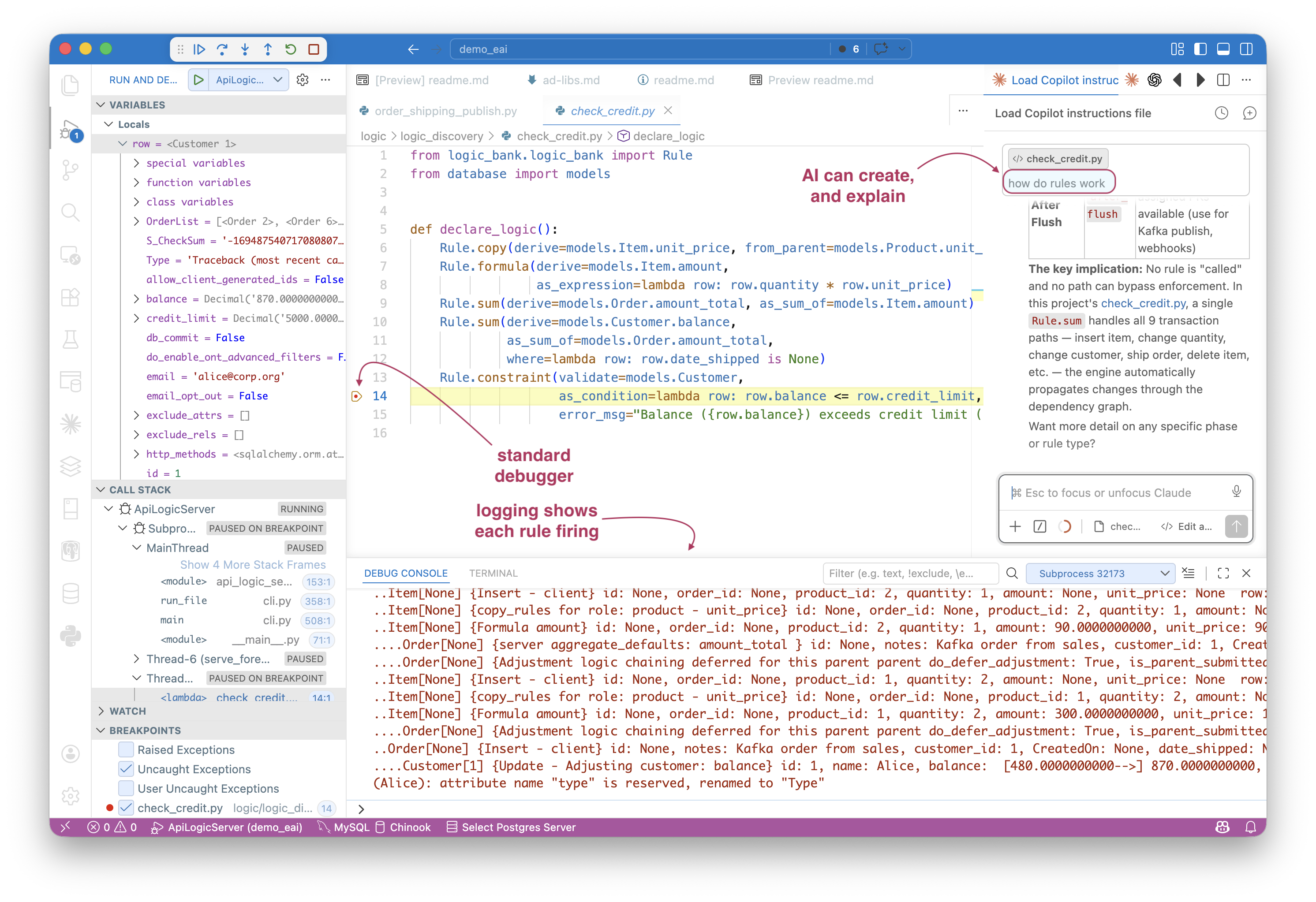
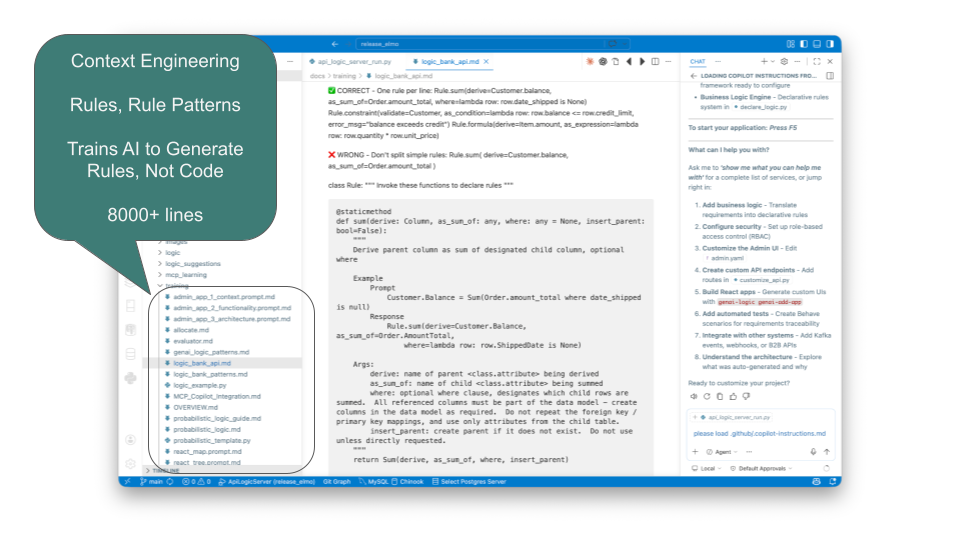
It depends on AI generating data rules, not Frankencode. This is not native to AI.
GenAI-Logic trains AI using Context Engineering — 8,000+ lines of curated rules, patterns, and examples that direct AI to produce declarative Data Rules rather than procedural code. This is not a system prompt. It took years to build, and it's what makes the difference between rules the engine can enforce and Frankencode it cannot.
Together: AI generates the rules. The engine enforces them. Neither is optional. Neither is a prompt.
Governance at Org Scale
The architecture above governs one project. The harder question is org scale — dozens of teams, hundreds of services, requirements flowing in from every direction. Most enterprises already have the front of this pipeline. Gherkin is established practice. Business analysts write scenarios. Product owners review them. They flow into Jira, into specs, into developer tickets. The pipeline exists. The question is what comes out the other end. Without a rules engine, Gherkin becomes procedural code. Each team interprets the spec, writes the handlers, wires up the paths. The same five-rule scenario produces 220 lines on one team, 340 on another — each with the path-dependency bugs no developer (and no AI) enumerates exhaustively. Multiply by every team, every quarter, every new endpoint, and governance reverts to a discipline problem at scale — which is to say, an unsolved problem. With GenAI-Logic, that same Gherkin produces declarative rules — automatically dependency-ordered, automatically enforced at commit, automatically inherited by every new path. The pipeline doesn't change. The output does. This is what makes governance an org-level architectural property rather than a per-project review burden. Gherkin is what the business already writes. The rules are the requirement, restated with precision. Governance becomes pipeline-native — not a layer bolted on, but the natural output of the workflow the org already runs.
Iteration at Scale
A real system isn't five rules. It's hundreds. And iteration isn't optional — it's the entire job.
Most AI storefronts solve iteration by regenerating the system. That works for screens. For logic, every regeneration is a new probabilistic output — which means new bugs, every time. At five rules you might catch them. At five hundred you won't.
GenAI-Logic iterates differently. New requirements add new rules; the engine recomputes dependencies automatically. Existing logic isn't regenerated, it's preserved. The human stays in the loop on two surfaces:
- The rules themselves — short, readable, traceable to the spec. The rule is the requirement, restated with precision. Review them in the IDE, adjust as needed.
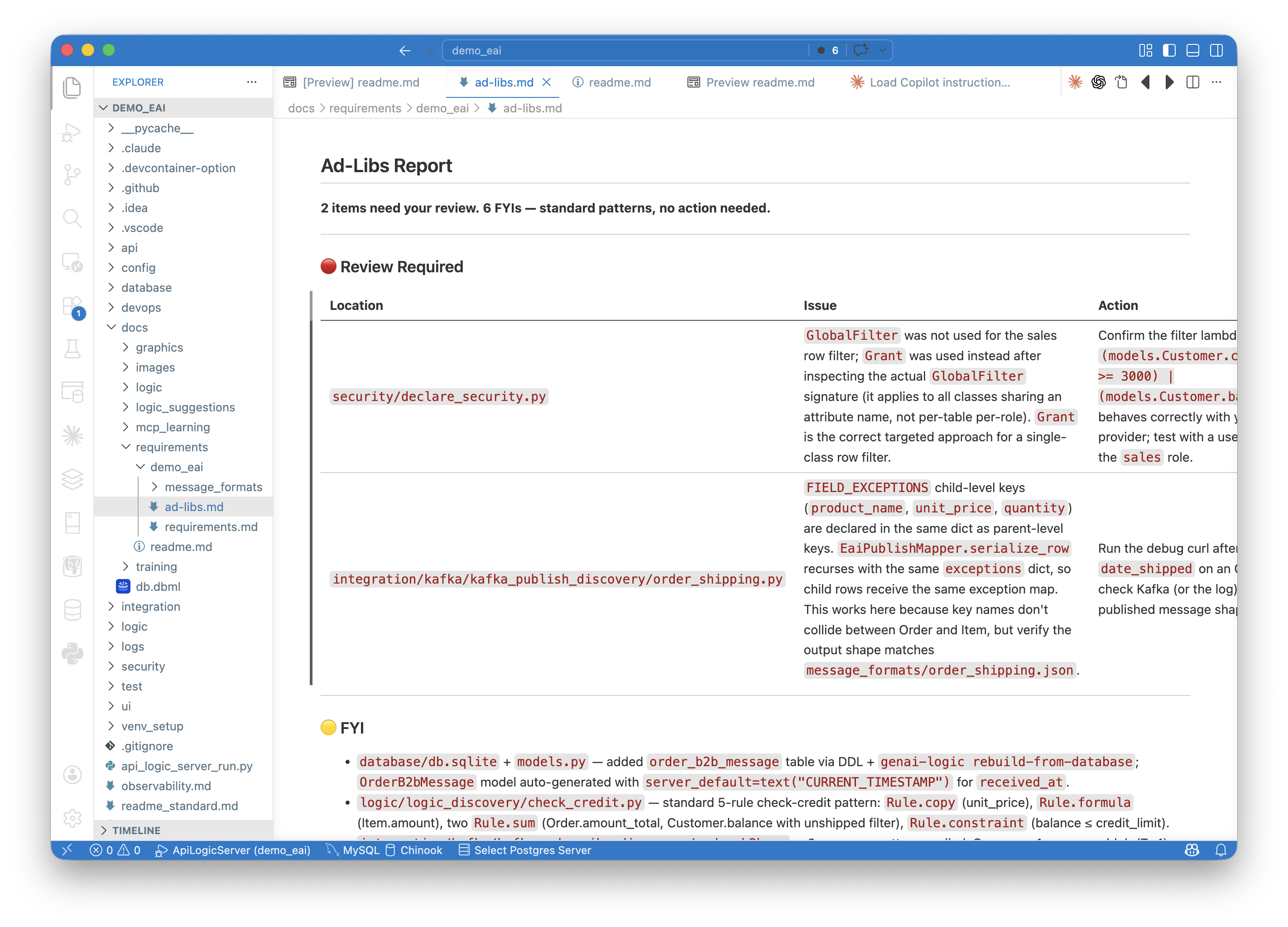
- The ad-libs report — every decision AI made beyond the spec, flagged for review or recorded as standard pattern. Tighten the spec, re-run; the loop converges.
This is what makes the system maintainable at enterprise scale: rigorous translation of intent into rules, reviewed by humans, executed by the engine. Not regenerated. Not approximated. Enforced.
Business Impact
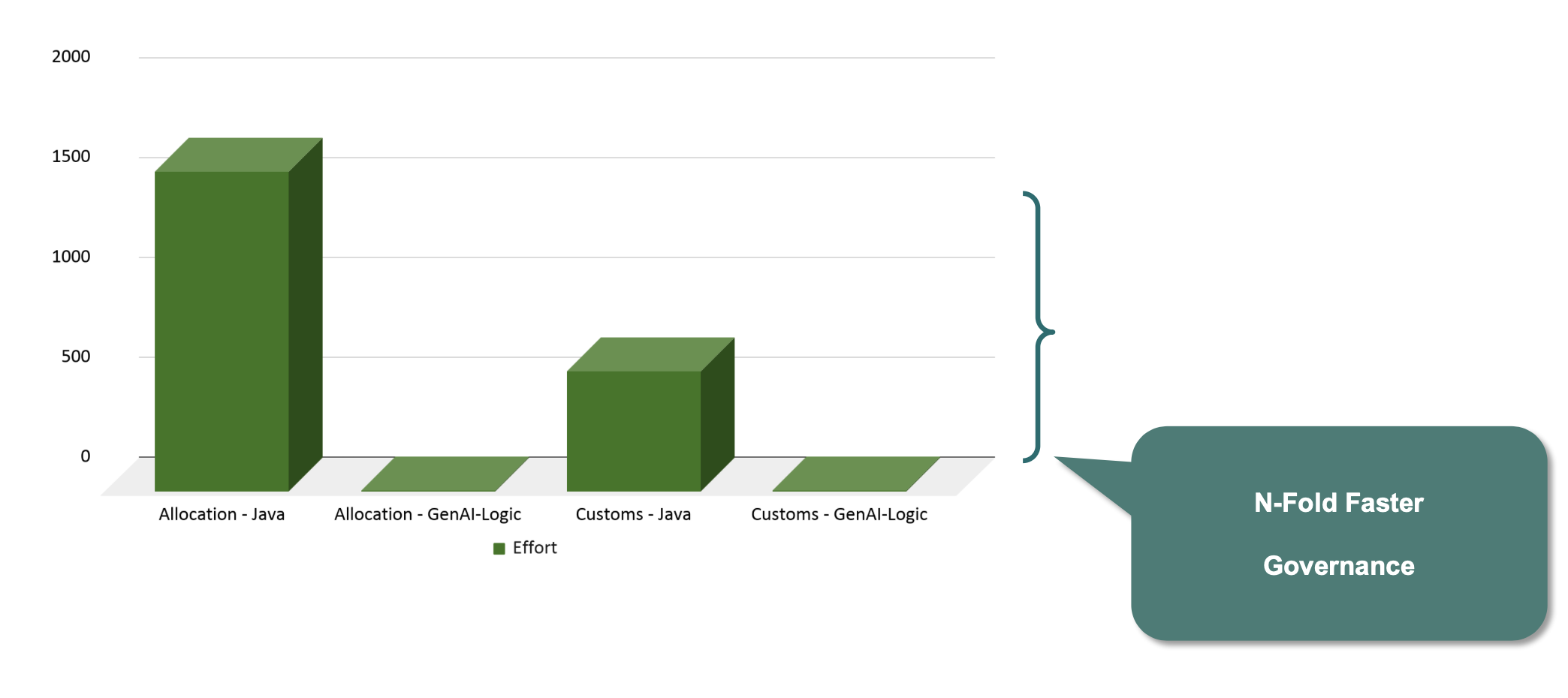
The rules are the requirement — restated with precision. They're what runs, what auditors review, and what every path inherits. They can't drift from what they enforce.
And because governance is architectural — not disciplinary — the agility follows. One prompt replaced 4 developers × 2 years (Allocation). XR replaced months of traditional framework work (Customs, and the requirements).
Governance and agility are not a tradeoff. They're the same architecture.
It's free and open source. Five minutes to install, then say 'guide me' — the automated tutorial walks you through debugging, performance, and the full architecture hands-on.